2025

NVR: Vector Runahead on NPUs for Sparse Memory Access
Hui Wang*, Zhengpeng Zhao*, Jing Wang, Yushu Du, Yuan Cheng, Bing Guo, He Xiao, Chenhao Ma, Xiaomeng Han, Dean You, Jiapeng Guan, Ran Wei, Dawei Yang♢, Zhe Jiang♢ (* equal contribution, ♢ corresponding author)
Design Automation Conference (DAC) 2025 Oral
Deep Neural Networks are increasingly leveraging sparsity to reduce the scaling up of model parameter size. However, reducing wall-clock time through sparsity and pruning remains challenging due to irregular memory access patterns, leading to frequent cache misses. In this paper, we present NPU Vector Runahead (NVR), a prefetching mechanism tailored for NPUs to address cache miss problems in sparse DNN workloads. Rather than optimising memory patterns with high overhead and poor portability, NVR adapts runahead execution to the unique architecture of NPUs. NVR provides a general micro-architectural solution for sparse DNN workloads without requiring compiler or algorithmic support, operating as a decoupled, speculative, lightweight hardware sub-thread alongside the NPU, with minimal hardware overhead (under 5%). NVR achieves an average 90% reduction in cache misses compared to SOTA prefetching in general-purpose processors, delivering 4x average speedup on sparse workloads versus NPUs without prefetching. Moreover, we investigate the advantages of incorporating a small cache (16KB) into the NPU combined with NVR. Our evaluation shows that expanding this modest cache delivers 5x higher performance benefits than increasing the L2 cache size by the same amount.
NVR: Vector Runahead on NPUs for Sparse Memory Access
Hui Wang*, Zhengpeng Zhao*, Jing Wang, Yushu Du, Yuan Cheng, Bing Guo, He Xiao, Chenhao Ma, Xiaomeng Han, Dean You, Jiapeng Guan, Ran Wei, Dawei Yang♢, Zhe Jiang♢ (* equal contribution, ♢ corresponding author)
Design Automation Conference (DAC) 2025 Oral
Deep Neural Networks are increasingly leveraging sparsity to reduce the scaling up of model parameter size. However, reducing wall-clock time through sparsity and pruning remains challenging due to irregular memory access patterns, leading to frequent cache misses. In this paper, we present NPU Vector Runahead (NVR), a prefetching mechanism tailored for NPUs to address cache miss problems in sparse DNN workloads. Rather than optimising memory patterns with high overhead and poor portability, NVR adapts runahead execution to the unique architecture of NPUs. NVR provides a general micro-architectural solution for sparse DNN workloads without requiring compiler or algorithmic support, operating as a decoupled, speculative, lightweight hardware sub-thread alongside the NPU, with minimal hardware overhead (under 5%). NVR achieves an average 90% reduction in cache misses compared to SOTA prefetching in general-purpose processors, delivering 4x average speedup on sparse workloads versus NPUs without prefetching. Moreover, we investigate the advantages of incorporating a small cache (16KB) into the NPU combined with NVR. Our evaluation shows that expanding this modest cache delivers 5x higher performance benefits than increasing the L2 cache size by the same amount.
2024
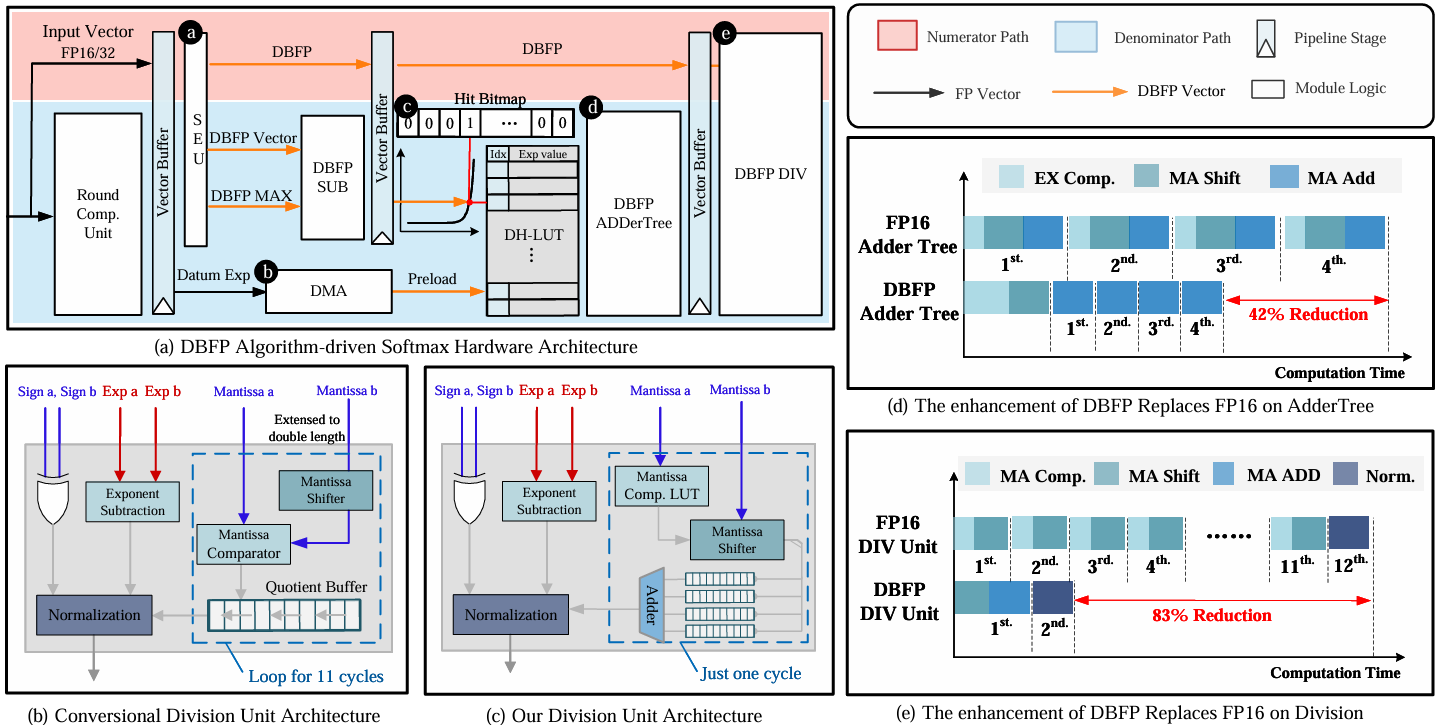
Pushing the Limits of BFP on Narrow Precision LLM Inference
Hui Wang*, Yuan Cheng*, Xiaomeng Han, Zhengpeng Zhao, Dawei Yang♢, Zhe Jiang♢ (* equal contribution, ♢ corresponding author)
AAAI Conference on Artificial Intelligence (AAAI) 2025
The substantial computational and memory demands of Large Language Models (LLMs) present barriers to their deployment. Block Floating Point (BFP) has been instrumental in accelerating linear operations, which are fundamental to LLM workloads. However, as the sequence length of LLMs increases, nonlinear operations have increasingly become performance bottlenecks, with Attention being a typical example due to its computational complexity scaling quadratically with input length. These nonlinear operations continue to be predominantly executed using inefficient floating-point formats, which renders the system challenging to optimize software efficiency and hardware overhead. In this paper, we delve into the limitations and potential of applying BFP to nonlinear operations. Given our findings, we introduce a novel hardware-software co-design framework (DB-Attn), including: (i) DBFP, an advanced BFP version, overcomes nonlinear operation challenges with a pivot-focus strategy for diverse data and an adaptive grouping strategy for flexible exponent sharing. (ii) DH-LUT, a novel lookup table algorithm dedicated to accelerating nonlinear operations with DBFP format. (iii) An RTL-level DBFP-based engine is implemented to support DB-Attn, applicable to FPGA and ASIC. Results show that DB-Attn provides significant performance improvements with negligible accuracy loss, achieving 74% GPU speedup on Softmax of LLaMA and 10x low-overhead performance improvement over SOTA ASIC designs.
Pushing the Limits of BFP on Narrow Precision LLM Inference
Hui Wang*, Yuan Cheng*, Xiaomeng Han, Zhengpeng Zhao, Dawei Yang♢, Zhe Jiang♢ (* equal contribution, ♢ corresponding author)
AAAI Conference on Artificial Intelligence (AAAI) 2025
The substantial computational and memory demands of Large Language Models (LLMs) present barriers to their deployment. Block Floating Point (BFP) has been instrumental in accelerating linear operations, which are fundamental to LLM workloads. However, as the sequence length of LLMs increases, nonlinear operations have increasingly become performance bottlenecks, with Attention being a typical example due to its computational complexity scaling quadratically with input length. These nonlinear operations continue to be predominantly executed using inefficient floating-point formats, which renders the system challenging to optimize software efficiency and hardware overhead. In this paper, we delve into the limitations and potential of applying BFP to nonlinear operations. Given our findings, we introduce a novel hardware-software co-design framework (DB-Attn), including: (i) DBFP, an advanced BFP version, overcomes nonlinear operation challenges with a pivot-focus strategy for diverse data and an adaptive grouping strategy for flexible exponent sharing. (ii) DH-LUT, a novel lookup table algorithm dedicated to accelerating nonlinear operations with DBFP format. (iii) An RTL-level DBFP-based engine is implemented to support DB-Attn, applicable to FPGA and ASIC. Results show that DB-Attn provides significant performance improvements with negligible accuracy loss, achieving 74% GPU speedup on Softmax of LLaMA and 10x low-overhead performance improvement over SOTA ASIC designs.